


Most AI users think “more context = better output,” but past a point, adding more tokens quietly makes your AI dumber.
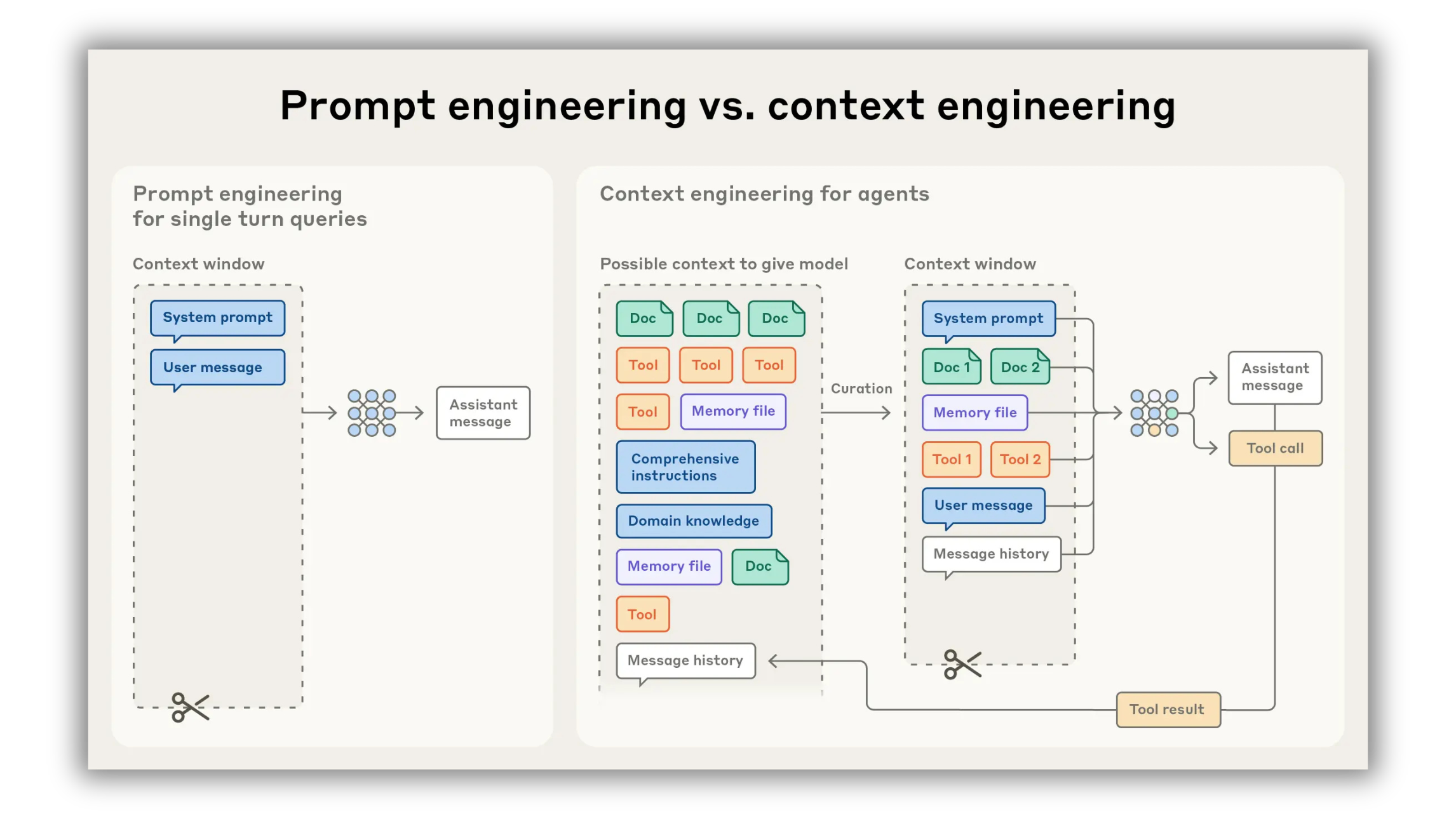
Here’s the uncomfortable truth: LLMs have an attention budget. Every extra token competes for limited working memory, so stuffing prompts, pasting entire docs, and hoarding examples dilutes the model’s focus. Anthropic just released an entire breakdown on “Effective context engineering for AI agents,” saying we should treat tokens as a finite resource you curate with intention.
The goal isn’t maximal context; it’s the smallest possible set of high-signal tokens that maximize the likelihood of the exact outcome you want. When you do this well, you get sharper answers, fewer hallucinations, faster runs, and lower costs.
Today, I’m going to hand you seven rules and a field-tested workflow to keep your models laser-focused.
Let’s dive in.
1. Start with the desired artifact, not the prompt
Most “context bloat” starts because people write prompts before they define success. Flip it.
Define the artifact: one sentence that describes format + purpose. Example: “A 600-word, step-by-step onboarding email that drives new trial users to connect Stripe within 24 hours.”
List acceptance criteria: 5–8 bullet points the output must satisfy (tone, must-include facts, banned claims, success metric).
Reverse-map context: for each criterion, ask “What’s the least information the model needs to satisfy this?” That becomes your context shopping list.
Do this and you’ll immediately stop pasting entire wikis. You’ll paste exactly what the artifact requires—nothing more.
2. Package knowledge as JSON, not paragraphs
Paragraphs blur signal and waste tokens. Structured context forces compression, makes retrieval precise, and keeps the model on rails.
Minimal JSON patterns that punch above their weight:
Voice DNA: { tone, temperature, formality, directness, syntax_examples }
ICP: { segment_name, job_to_be_done, pains, triggers, objections, words_they_use }
Product: { promise, 3 core features, 3 proof points, banned claims, compliance_notes }
Offer: { price, terms, bonuses, guarantee, deadline, CTA_variations }
My most engaged readers consistently respond to this shift—context structuring, JSON formatting, and context libraries rank among the highest-performing topics for AI Disruptor, which is why I keep teaching them. And it aligns with my core mission: teach effective communication with AI through structured systems, not random prompts.
3. Curate 1–3 canonical examples, not a zoo
Examples are potent, but more is not better. Pick only canonical patterns that demonstrate:
The exact format you want.
The voice and constraints that matter.
One tricky edge case the model must handle.
Label each example with a name and a one-line “why this matters.” If an example isn’t uniquely useful, it’s noise.
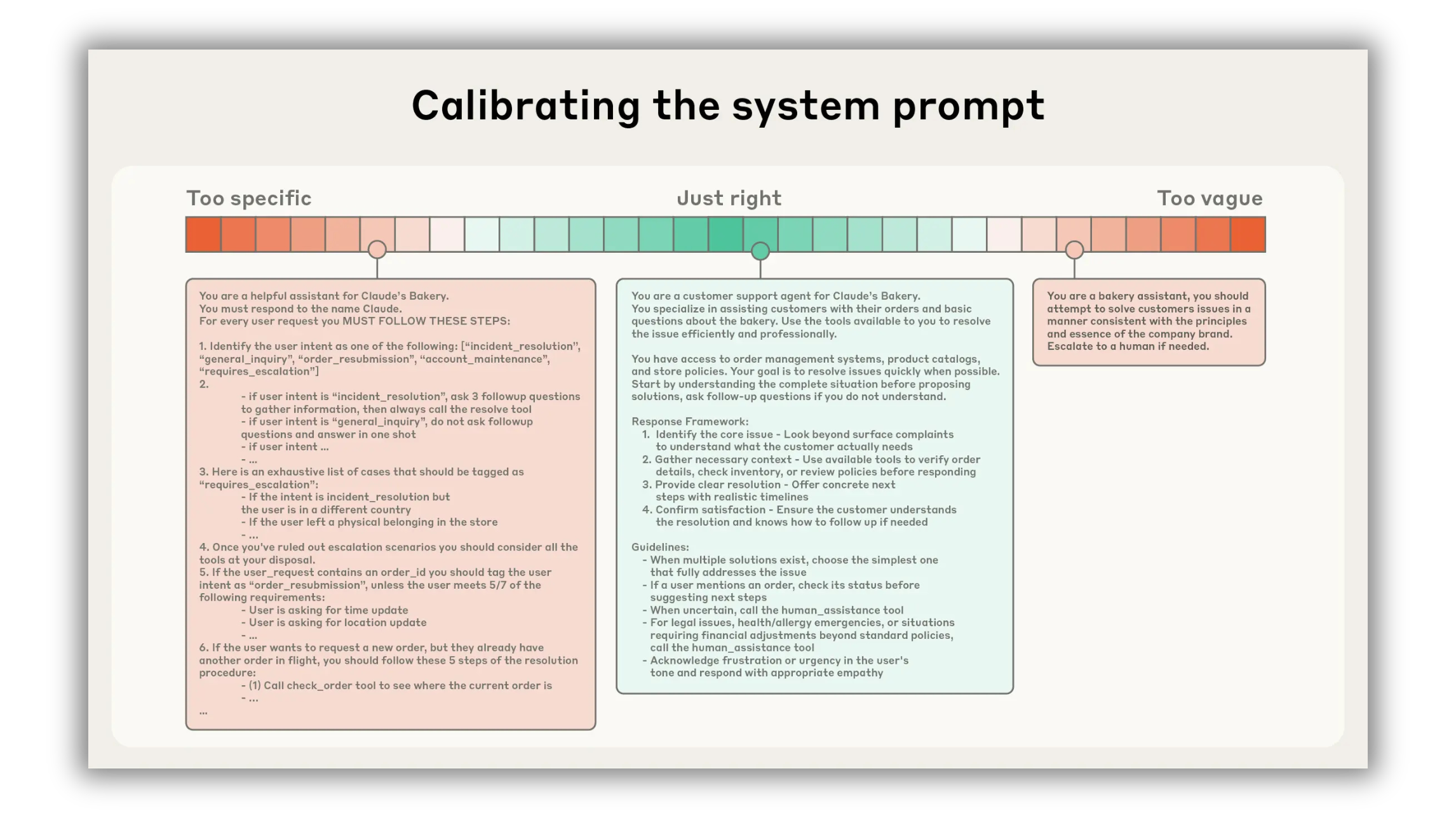
4. Engineer “right altitude” system instructions
Prompts fail in two ways: brittle hardcoding or vague platitudes. Write instructions at the right altitude. They should be clear enough to guide behavior, flexible enough to generalize.
A simple structure that works:
Role and mission: “You are an AI Assistant. Your job is to produce [artifact] that meets [acceptance criteria].”
Guardrails: bullets for banned moves, compliance, do/do-not lists.
Process: numbered steps the model should follow every time.
Output contract: schema or headings the model must fill.
Make each section explicit and minimal. If you can’t point to how a sentence increases accuracy, delete it.
5. Retrieve just-in-time, don’t front-load
Preloading entire docs burns attention on irrelevant text. Instead, store lightweight identifiers and fetch on-demand:
Keep “handles,” not blobs: file paths, section anchors, vector IDs, or web links.
Teach the model to ask: “If criterion X is missing, retrieve Y from Z.”
Use tool outputs that are token-efficient: summaries, bullet highlights, or field extractions, not the raw document.
A hybrid approach is best: preload only what is universally required across runs; fetch everything else at runtime. It’s faster than pure exploration and leaner than stuffing.
6. Budget tokens like cash
Treat tokens as line items with ROI. Before you add anything, ask:
Does this token increase the probability of hitting the acceptance criteria?
Can I compress this into a label, enum, or pointer?
What can I collapse into JSON fields, headings, or short bullet points?
Practical caps you can adopt today:
System instructions: 300–600 tokens.
Canonical examples: 1–3, each 120–250 tokens.
Context assets: 200–500 tokens per asset (after compression).
Conversation history: pin only the last 1–2 turns plus a running “scratchpad summary.”
7. Instrument, compare, prune
Context engineering is iterative. Build feedback into your loop:
Create a regression suite: representative inputs you’ll re-run after every change.
Prune ruthlessly: remove any section that doesn’t improve metrics; re-test to confirm no performance drop.
Make pruning a first-class habit. You’ll be shocked how much context you can delete without losing quality.
How to practice and apply this in 20 minutes
Write the artifact sentence and acceptance criteria. Keep the criteria concrete and testable.
Convert your raw notes into three JSON assets: Voice DNA, ICP, Product/Offer. Limit to 8–12 fields each.
Choose one canonical example. Annotate why it’s included.
Write “right altitude” system instructions in four labeled sections: role/mission, guardrails, process, output contract.
Identify the 1–3 pieces you were about to paste in full. Replace them with a more general context profile.
Log failures.
Prune or compress anything that didn’t move the needle. Re-run.
Once you see how lean systems beat bloated prompts in both quality and cost, the debate ends.
Why this matters right now
AI Disruptor exists to turn you into a high-leverage AI operator—someone who can build systems that work, not just write clever prompts. Structuring context, writing at the right altitude, and packaging knowledge as reusable assets are the highest-ROI skills in this era. That’s been my focus across the publication and programs, because it consistently delivers the best outcomes for readers and clients alike.
If you implement only two ideas from today:
Replace paragraphs with JSON assets.
Spend considerable time on perfecting your project/system instructions.
You’ll see immediate gains in accuracy, speed, and cost, without touching the model.
Let’s go build leaner systems.
— Alex
Founder of AI WriterOps
Founder of AI Disruptor
Alex, you are the MAN!
Let me put this into NLM and start to study it step by step.
Are you okay with that, Alex?