DeepSeek's moment: Beyond the $5.6M hype and market panic
Many are claiming the U.S. AI industry is a fraud in this big moment.

Alright, let's talk about DeepSeek.
I won’t repeat everything that’s out there already, but we should know a lot about the AI tools we use and companies behind them.
Not just the headlines, not just the hype, but everything you actually need to understand about this moment in AI.
And this is a huge moment in AI and geopolitics.
Over the last week, I've watched the world go crazy over this Chinese AI startup. Headlines screaming about market crashes, revolutionary technology, and the end of expensive AI development.
Here in Brazil, there's a narrative taking hold - and I'm sure this is the same in many other countries. It goes something like this: China just proved that the entire U.S. AI industry is built on a lie. That all those billions poured into OpenAI and others? Just another case of Silicon Valley excess, exposed by DeepSeek's $5.6M miracle.
It's a compelling story.
It hits all the right notes about American tech capitalism and its excesses. And sure, there is some truth in there.
But there is way more to this story.
And yes, $1.2 trillion getting wiped from the US stock market is a big deal.
But this market reaction isn't just about DeepSeek. It's about something much more fundamental happening in AI development.
Let me break this down properly.
First, the raw numbers: Nvidia dropped 16.86% in a single day. Constellation plunged 20.85%. Nebius Group? A staggering 37.44% drop. But these aren't just random fluctuations – they're the market grappling with a crucial question: Is the economics of AI development about to fundamentally change?
The conventional wisdom was simple: Building state-of-the-art AI requires billions in hardware investment. The big players – OpenAI, Anthropic, Google – they've all followed this playbook. Massive GPU clusters, enormous power bills, and eye-watering development costs.
Then DeepSeek shows up with people claiming they've built a competitive model for $5.6 million.
The market didn't just panic because of DeepSeek's claims. It panicked because if those claims are true, the entire economic model of AI development needs to be rewritten.
The market is treating this as a simple story. The reality is far more complex.
We're watching a collision between different approaches to AI development – the brute force scaling of U.S. companies versus claims of radical efficiency improvements from newcomers.
The market is confused.
It's actually rational. Because what's happening here isn't just about market prices or even about DeepSeek. It's about three massive shifts colliding at once:
The economics of AI development
The geopolitics of AI competition
The technical race for efficiency
And that's why this market panic is different.

What DeepSeek is and isn’t
Let's break down what we're actually looking at:
DeepSeek V3 is a 671-billion-parameter model with a clever twist: it uses a mixture-of-experts (MoE) approach that only activates 37 billion parameters for each token.
The training specs (according to DeepSeek) are interesting:
2,048 Nvidia H800 GPUs
57 days of training time
2.78 million GPU hours total
For comparison? Meta needed about 30.8 million GPU hours to train Llama 3. That's a massive difference in computational requirements.
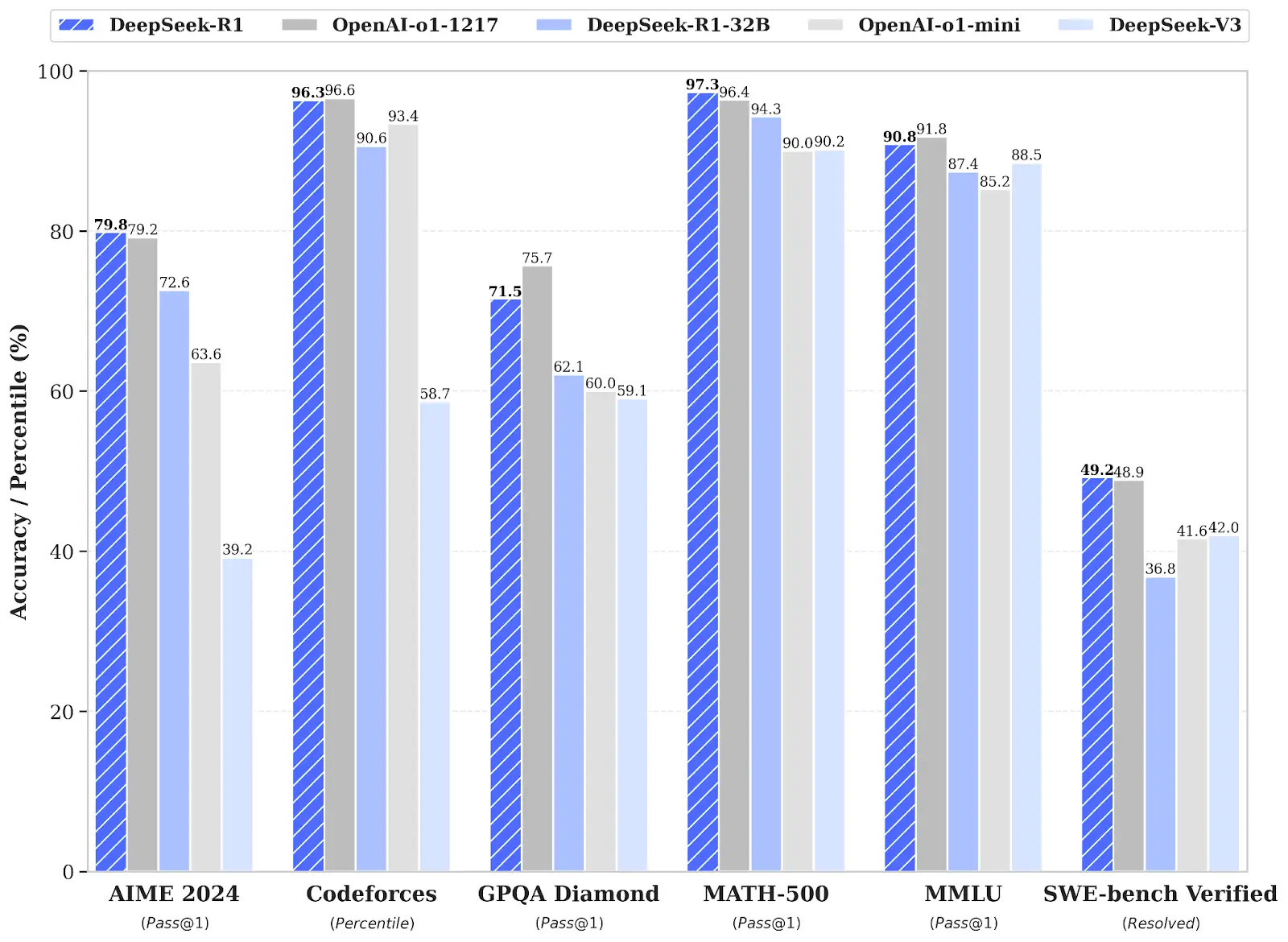
Then there's R1, their reasoning model. The benchmarks here are what really caught everyone's attention - scores that closely match OpenAI's models on major tests.
DeepSeek's approach is fundamentally different from the brute force scaling we've seen from other companies. They're using what they call Multi-head Latent Attention (MLA) and DeepSeekMoE - architectures designed to compress information without losing meaning.
This means:
Lower memory requirements during inference
Reduced computational needs
More efficient processing of each token
DeepSeek is also open source. And that is one of the key takeaways here.
DeepSeek's approach combines a few things that we should all be excited about:
State-of-the-art performance claims
Open-source access
Efficient architecture that can run locally
Six smaller versions designed for laptop deployment
This is why the tech community is actually excited (beyond the market drama).
We're looking at models that are:
Efficient enough to run locally
Open for modification and improvement
Competitive with closed-source giants
Ready for real-world deployment
This will accelerate the trend toward:
More efficient AI development
Localized AI processing
Customizable models for specific use cases
Faster innovation cycles
Check out these benchmarks. They are impressive: