


The tool I wish I had before training my AI
It fuses your entire archive into a single document.

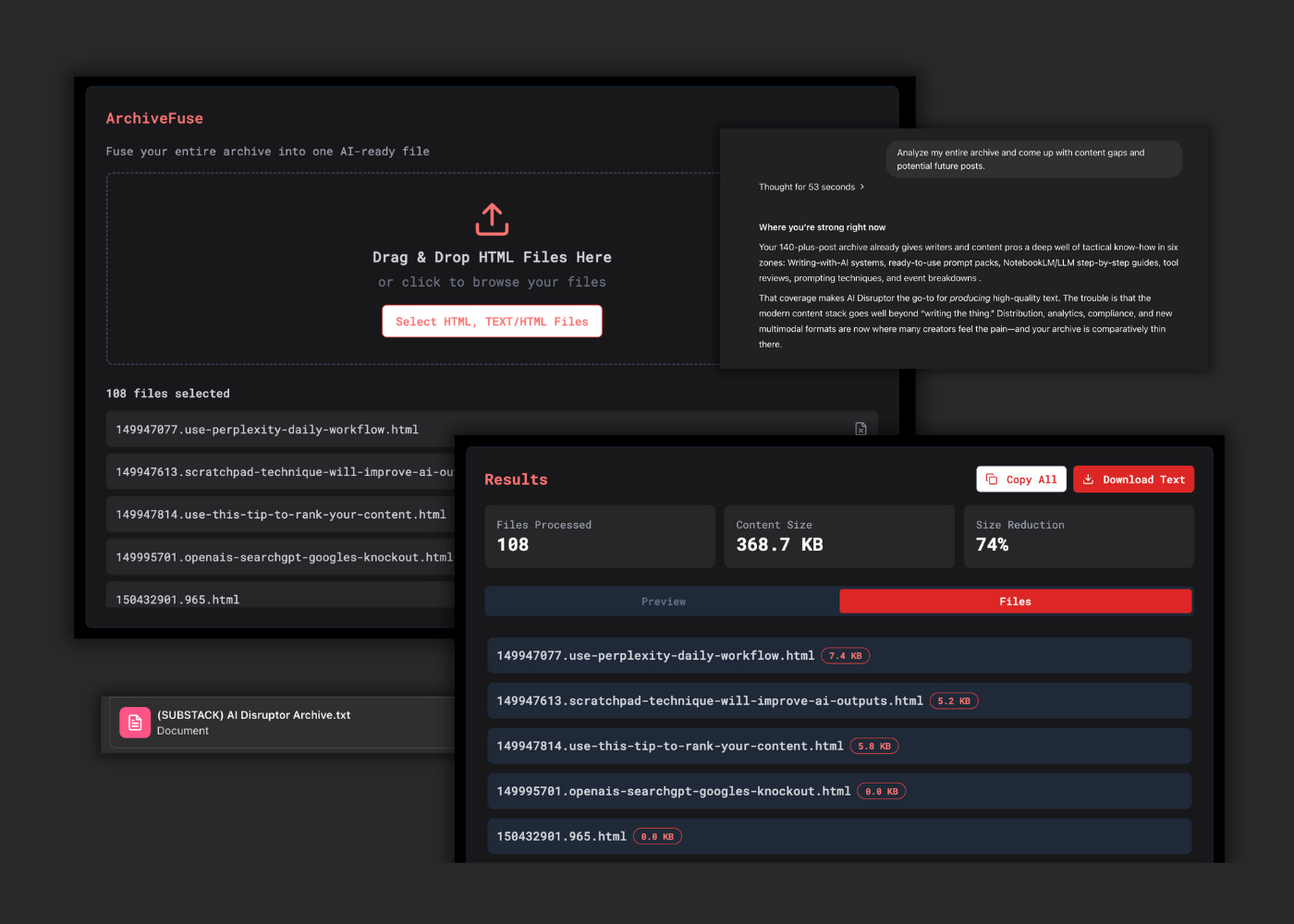
When I exported my Substack for the first time, I got hundreds of HTML files—all scattered and definitely not something I could upload easily to ChatGPT or Claude. It was digital clutter.
If you’ve ever tried to feed your writing to your AI assistant, you know the blocker: you can’t train it on hundreds of HTML files one-by-one.
So I built a better way.
AI can’t help you if it can’t access your archive
We talk about using AI to “write in our voice.” But here’s the thing:
Your AI can’t sound like you if it doesn’t know what you’ve written.
The modern content stack gives us tools like ChatGPT and Claude Projects, where you can upload docs, search them, analyze them, and build entire workflows around your work.
But Substack (and other platforms) don’t give you the most usable file. They give you a folder full of HTML.
ArchiveFuse fuses every post into one AI-ready document
ArchiveFuse is a simple tool I built to compress your entire newsletter export into one clean, prompt-ready .txt file.
No code. No formatting issues. No more post-by-post uploads.
Here’s how it works:
Export your newsletter from Substack (or any platform).
Drag the HTML files into ArchiveFuse.
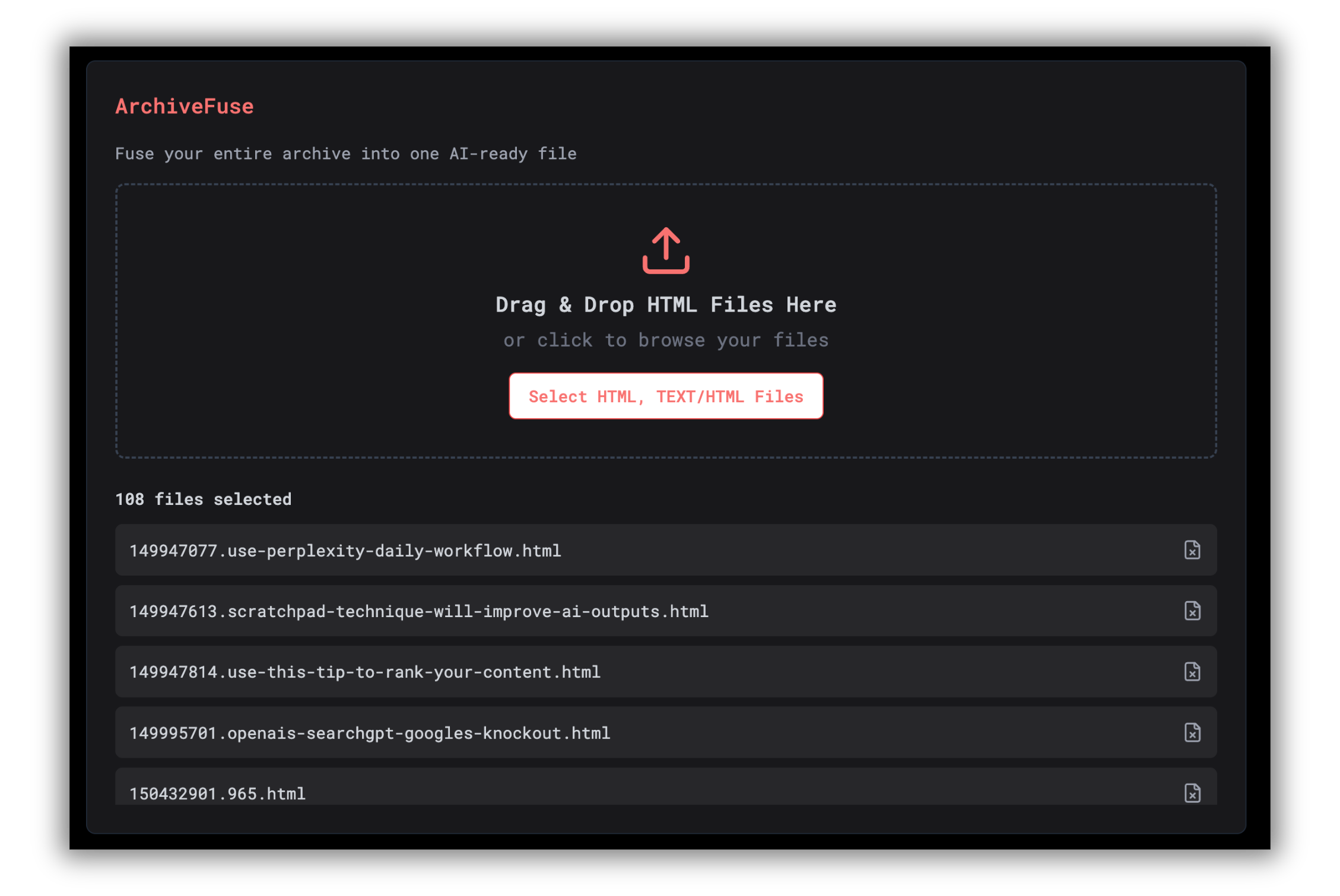
Download your fused
.txtfile.
That’s it. No setup. No scripts. Just one file, ready to upload.
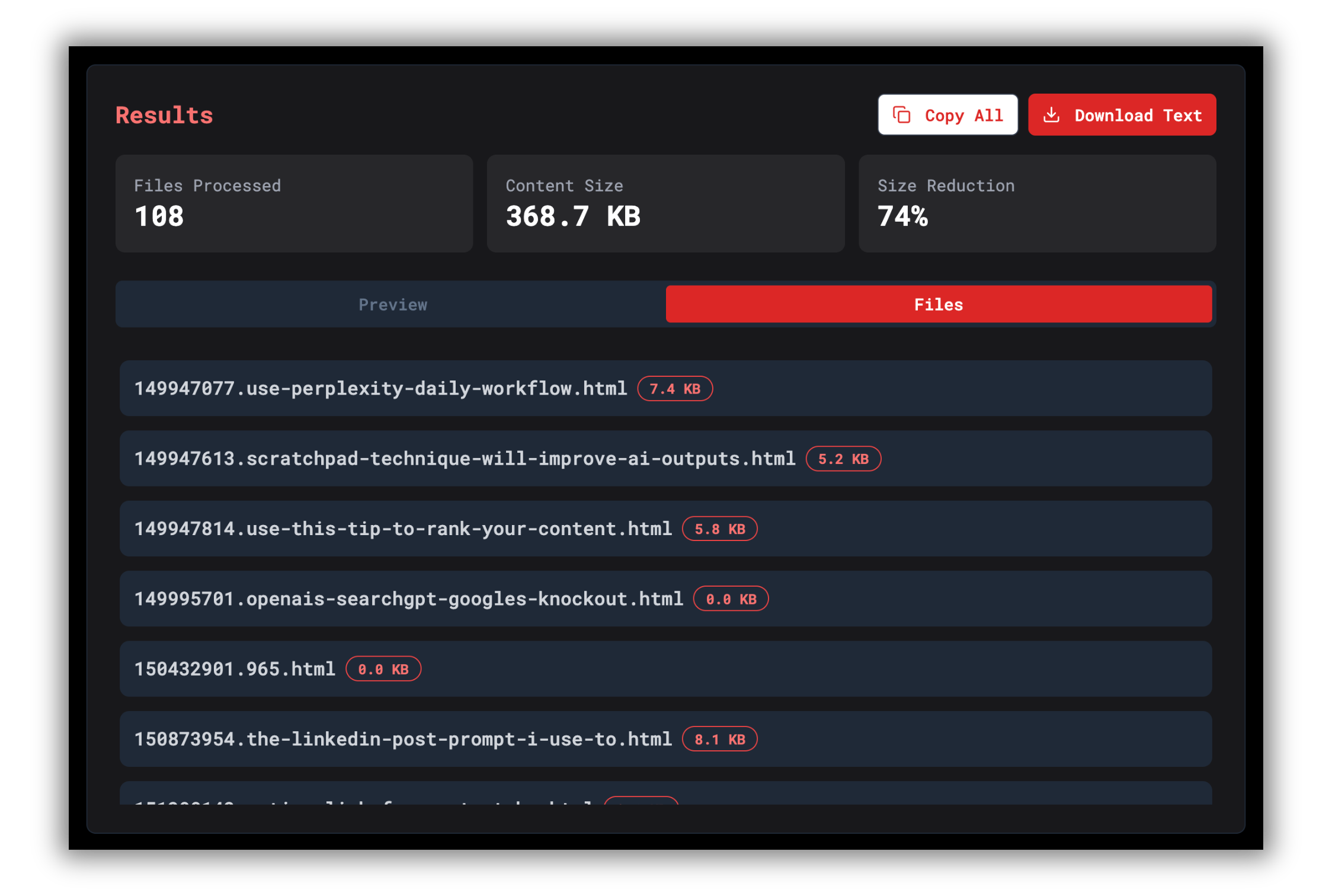
Upload your fused archive to ChatGPT or Claude Projects
Let me show you a simple flow you can use to test it out.
Go to ChatGPT and open up a new AI writing project if you don’t have one already.
Upload the
.txtfile just fused with ArchiveFuse to your project knowledge.Now ChatGPT has access to every post—and it knows:
Your writing style
Your topic zones
Your voice and structure
What you’ve already covered
From here, you can:
Ask ChatGPT to analyze content gaps
Generate high-impact post ideas
Run voice consistency checks
Plan repurposing strategies from past pieces
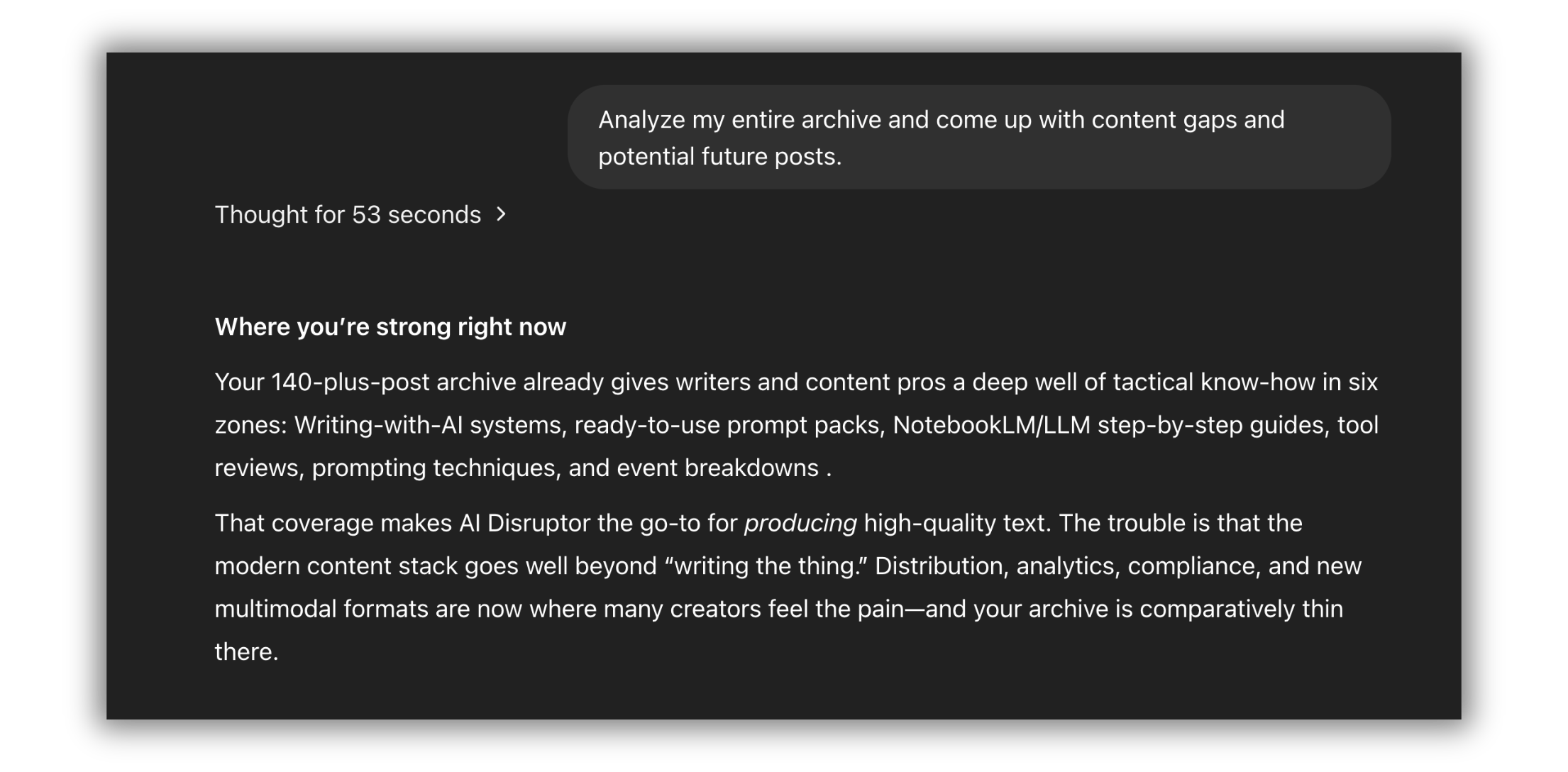
It’s one of the biggest unlocks for scaling a solo writing operation.
This is just the first workflow we’re going to build on top of ArchiveFuse.
Access the ArchiveFuse tool here: